Python 脫逸字元清單 Escape Sequence (ASCII Table)
2021-08-12
筆記 Python 各式脫逸字元、跳脫字元(Escape Sequence),包含 newline、return、Backspace、TAB、Octal Value、Hex Value 以及 Unicode Codepoint 以及 Unicode Name 等清單。
說明
在程式語言當中,某些特殊字元有其特別的涵義,例如反斜線、單引號、雙引號。而如果想要表達的正是該字元本身,而非觸發它的特殊涵義,則要藉由脫逸字元的方式來輸出。此外反斜線與其他字元構成了特殊的字元組合,有豐富的使用意涵,例如最常見的換行符號、Tab分段符號。
List of Python Escape Sequence
| Escape Sequence | Meaning |
|---|---|
| |反斜線 Backslash | |
| ' | 單引號, Single quote |
| " | 雙引號, Double quote |
| \a | 主機板嗶聲, ASCII Bell (BEL) |
| \b | 移除前字元, ASCII Backspace (BS) |
| \f | ASCII Formfeed (FF) |
| \n | 換行符號, ASCII Linefeed (LF) |
| \r | 回車符號, ASCII Carriage Return (CR) |
| \t | Tab分段, ASCII Horizontal Tab (TAB) |
| \v | ASCII Vertical Tab (VT) |
| \ooo | 用 8 進位表示 ASCII Table 字元 |
| \xhh | 用 16 進位表示 ASCII Table 字元 |
| \N{name} | 用 Unicode Name 表示 Unicode 字元 |
| \uxxxx | 使用 16位元 Hex 進位表示 Unicode 字元 |
| \Uxxxxxxxx | 使用 32位元 Hex 進位表示 Unicode 字元 |
Examples
用 8 進位表示 ASCII Table 字元
# oct(101) = dec(65) = 'A'
print('\101')
# A
# oct(065) = dec(53) = '5'
print('\065')
# 5
# 65 auto zfill to 065
print('\65')
# 5詳細可以參照 ASCII Table 的對照,值得一提的是如果再繁體中文作業系統環境,如果輸入 \3 會顯示 ♥ ,這是怎麼一回事?按理要顯示的是 \003 也就是 ASCII Table 中的 ETX (end of text),只是因為這是特殊控制字元無法顯示,作業系統經歷尚無法名狀的過程將其顯示為 ♥ ,才出現了這個情境 🙂
用 16 進位表示 ASCII Table 字元
# hex(41) = dec(65) = 'A'
print('\x41')
# A
# hex(35) = dec(53) = '5'
print('\x35')
# 5表示 Unicode 字元
以「資」字作為示範:

print('\u8CC7')
# 資
print('\U00008CC7')
# 資
print('\N{CJK UNIFIED IDEOGRAPH-8CC7}')
# 資⚠️使用 Unicdoe Name 的時候特殊的 Unicode Plane 需使用 UPPER CASE 才不會發生 (unicode error) 'unicodeescape' codec can't decode bytes in position 0-29: unknown Unicode character name 的報錯。
有關於 Encoding
接著想要談一下關於 Encoding 的那些事,讓編碼的觀念連結再一起。觀察上圖我們可以發現關於「資」的各編碼值如下:
HTML Entity 為 資 、 資
UTF8 Encoding 為 0xE8 0xB3 0x87
UTF16 Encoding 為 0x8CC7
UTF32 Encoding 為 0x00008CC7
而在 Python 中該如何產生這些編碼值?方法如下
type('\u8CC7')
# str
'\u8CC7'.encode()
'\u8CC7'.encode('utf8')
# b'\xe8\xb3\x87'
'\u8CC7'.encode('utf16')
# b'\xff\xfe\xc7\x8c'
# UTF-16 Little Endian
'\u8CC7'.encode('utf32')
# b'\xff\xfe\x00\x00\xc7\x8c\x00\x00'
# UTF-32 Little Endian
'\u8CC7'.encode('big5')
# b'\xb8\xea'而如果現在的情境是只有編碼值,又該如何還原為編碼字元呢?
b'\xe8\xb3\x87'.decode()
# 資
b'\xff\xfe\xc7\x8c'.decode('utf16')
# 資
b'\xff\xfe\x00\x00\xc7\x8c\x00\x00'.decode('utf32')
# 資
b'\xb8\xea'.decode('big5')
# 資而在使用 Python 常見的編碼問題又是怎麼回事?例如下列這個「喆」這個字:
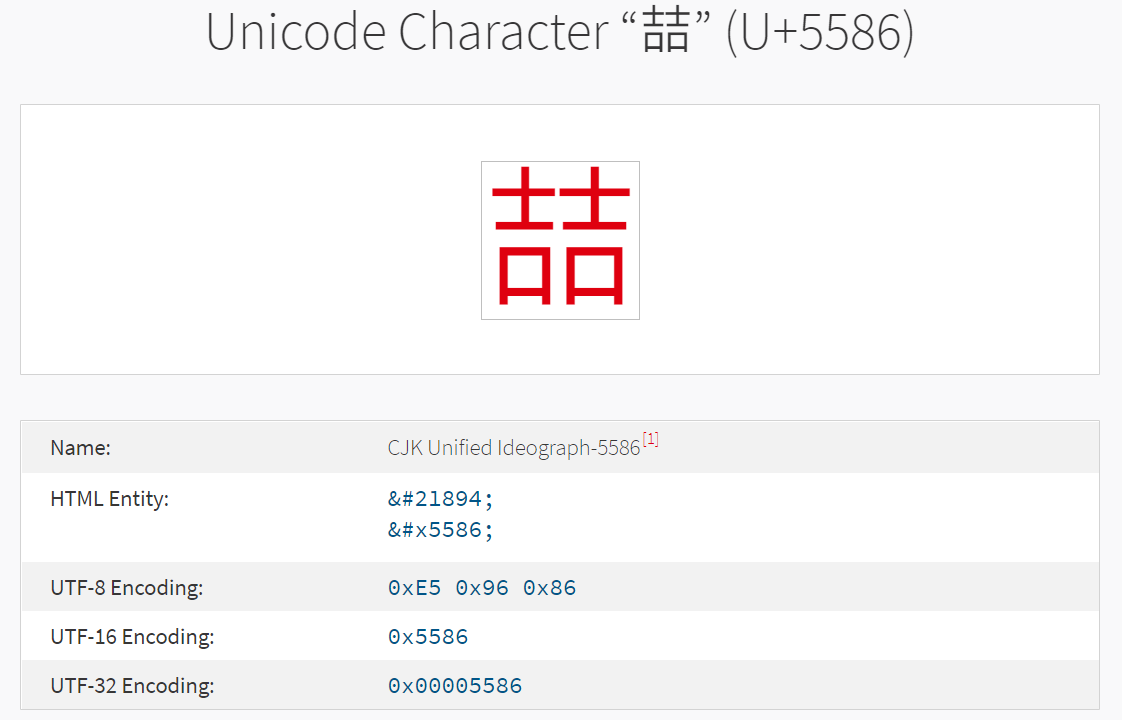
'\u5586'.encode()
# b'\xe5\x96\x85'但如果將這個字試圖以 big5 編碼,就會發生問題:
'\u5586'.encode('big5')UnicodeEncodeError: 'big5' codec can't encode character '\u5585' in position 0: illegal multibyte sequence
這個時候可以處理的方式有兩種:
(一)改採 UTF8 Encoding
(二)利用 encode 的 Optional Prameter errors 處理例外情形
# default, raise UnicodeError
'\u5586'.encode('big5', errors = 'strict')
'\u5586'.encode('big5', errors = 'ignore')
# b''除了 ignore 外,也可以採用 replace 的方式進行例外處理,replace 又分為下列幾種方式,其中 replace 或 backslashreplace 適合用於實際生產環境;namreplace 則適合用於除錯內容所使用。
'\u5586'.encode('big5', errors = 'replace')
# b'?'
# \uFFFD
'\u5586'.encode('big5', errors = 'xmlcharrefreplace')
# b'喆'
'\u5586'.encode('big5', errors = 'backslashreplace')
# b'\\u5586'
'\u5586'.encode('big5', errors = 'namereplace')
# b'\\N{CJK UNIFIED IDEOGRAPH-5586}'Disable Escape Sequence
在 string literal 前加註 r 就可以讓 Escape Sequence 不發揮作用。
r'\n'
# \nASCII Table
Generate ASCII Table.py
print(f'{"Char":4} {"Dec":3} {"Hex":>3} {"Oct":>3}')
for i in range(1, 129):
char = 'NUL' if i <= 32 or i >= 127 else chr(i)
decStr = str(i).zfill(3)
hexStr = str(hex(i)).replace("0x","").upper().zfill(2)
octStr = str(oct(i)).replace("0o","").zfill(3)
print(f'{char:4} {decStr:3} {hexStr:>3} {octStr:>3}')⚠️ 其中特殊的控制字元尚未正確標註。
| Char | Dec | Hex | Oct |
|---|---|---|---|
| NUL | 000 | 00 | 000 |
| SOH | 001 | 01 | 001 |
| STX | 002 | 02 | 002 |
| ETX | 003 | 03 | 003 |
| EOT | 004 | 04 | 004 |
| ENQ | 005 | 05 | 005 |
| ACK | 006 | 06 | 006 |
| BEL | 007 | 07 | 007 |
| BS | 008 | 08 | 010 |
| HT | 009 | 09 | 011 |
| LF | 010 | 0A | 012 |
| VT | 011 | 0B | 013 |
| FF | 012 | 0C | 014 |
| CR | 013 | 0D | 015 |
| SO | 014 | 0E | 016 |
| SI | 015 | 0F | 017 |
| DLE | 016 | 10 | 020 |
| DC1 | 017 | 11 | 021 |
| DC2 | 018 | 12 | 022 |
| DC3 | 019 | 13 | 023 |
| DC4 | 020 | 14 | 024 |
| NAK | 021 | 15 | 025 |
| SYN | 022 | 16 | 026 |
| ETB | 023 | 17 | 027 |
| CAN | 024 | 18 | 030 |
| EM | 025 | 19 | 031 |
| SUB | 026 | 1A | 032 |
| FSC | 027 | 1B | 033 |
| FS | 028 | 1C | 034 |
| GS | 029 | 1D | 035 |
| RS | 030 | 1E | 036 |
| US | 031 | 1F | 037 |
| SPACE | 032 | 20 | 040 |
| ! | 033 | 21 | 041 |
| " | 034 | 22 | 042 |
| # | 035 | 23 | 043 |
| $ | 036 | 24 | 044 |
| % | 037 | 25 | 045 |
| & | 038 | 26 | 046 |
| ' | 039 | 27 | 047 |
| ( | 040 | 28 | 050 |
| ) | 041 | 29 | 051 |
| * | 042 | 2A | 052 |
| + | 043 | 2B | 053 |
| , | 044 | 2C | 054 |
| - | 045 | 2D | 055 |
| . | 046 | 2E | 056 |
| / | 047 | 2F | 057 |
| 0 | 048 | 30 | 060 |
| 1 | 049 | 31 | 061 |
| 2 | 050 | 32 | 062 |
| 3 | 051 | 33 | 063 |
| 4 | 052 | 34 | 064 |
| 5 | 053 | 35 | 065 |
| 6 | 054 | 36 | 066 |
| 7 | 055 | 37 | 067 |
| 8 | 056 | 38 | 070 |
| 9 | 057 | 39 | 071 |
| : | 058 | 3A | 072 |
| ; | 059 | 3B | 073 |
| < | 060 | 3C | 074 |
| = | 061 | 3D | 075 |
| > | 062 | 3E | 076 |
| ? | 063 | 3F | 077 |
| @ | 064 | 40 | 100 |
| A | 065 | 41 | 101 |
| B | 066 | 42 | 102 |
| C | 067 | 43 | 103 |
| D | 068 | 44 | 104 |
| E | 069 | 45 | 105 |
| F | 070 | 46 | 106 |
| G | 071 | 47 | 107 |
| H | 072 | 48 | 110 |
| I | 073 | 49 | 111 |
| J | 074 | 4A | 112 |
| K | 075 | 4B | 113 |
| L | 076 | 4C | 114 |
| M | 077 | 4D | 115 |
| N | 078 | 4E | 116 |
| O | 079 | 4F | 117 |
| P | 080 | 50 | 120 |
| Q | 081 | 51 | 121 |
| R | 082 | 52 | 122 |
| S | 083 | 53 | 123 |
| T | 084 | 54 | 124 |
| U | 085 | 55 | 125 |
| V | 086 | 56 | 126 |
| W | 087 | 57 | 127 |
| X | 088 | 58 | 130 |
| Y | 089 | 59 | 131 |
| Z | 090 | 5A | 132 |
| [ | 091 | 5B | 133 |
| \ | 092 | 5C | 134 |
| ] | 093 | 5D | 135 |
| ^ | 094 | 5E | 136 |
| _ | 095 | 5F | 137 |
| ` | 096 | 60 | 140 |
| a | 097 | 61 | 141 |
| b | 098 | 62 | 142 |
| c | 099 | 63 | 143 |
| d | 100 | 64 | 144 |
| e | 101 | 65 | 145 |
| f | 102 | 66 | 146 |
| g | 103 | 67 | 147 |
| h | 104 | 68 | 150 |
| i | 105 | 69 | 151 |
| j | 106 | 6A | 152 |
| k | 107 | 6B | 153 |
| l | 108 | 6C | 154 |
| m | 109 | 6D | 155 |
| n | 110 | 6E | 156 |
| o | 111 | 6F | 157 |
| p | 112 | 70 | 160 |
| q | 113 | 71 | 161 |
| r | 114 | 72 | 162 |
| s | 115 | 73 | 163 |
| t | 116 | 74 | 164 |
| u | 117 | 75 | 165 |
| v | 118 | 76 | 166 |
| w | 119 | 77 | 167 |
| x | 120 | 78 | 170 |
| y | 121 | 79 | 171 |
| z | 122 | 7A | 172 |
| { | 123 | 7B | 173 |
| | | 124 | 7C | 174 |
| } | 125 | 7D | 175 |
| ~ | 126 | 7E | 176 |
| ~ | 127 | 7F | 177 |
| ~ | 128 | 80 | 200 |
參考資料
https://docs.python.org/3/reference/lexical_analysis.html
https://www.darkthread.net/cea
https://zi-hi.com/
https://www.compart.com/en/unicode/
https://docs.python.org/3/library/codecs.html