Redis Data Structures 常用的資料型別與資料結構
2024-12-11
筆記 Redis 常用的資料型別與資料結構,包含 String、List、Set、Sorted Set、Hash 等。

說明
因為 Redis 屬於 Schema free,所以不需要由資料庫管理員來定義資料表,可以隨時新增或刪除資料。
內建的資料結構各種 GET 與 SET 方法如下:
| Data Structure | GET | SET |
|---|---|---|
| Strings | GET | SET |
| Hashes | HGET | HSET |
| Lists | LINDEX | LPUSH |
| Sets | SPOP | SADD |
| Sorted Sets | ZRANGE | ZADD |
| HyperLogLog | PFCount | PFAdd |
| Bitmaps | BITCOUNT | SETBIT |
| Spatial Index | GEOPOS | GEOADD |
| Streams | XREAD | XADD |
Redis 屬於 Key-Value 的資料庫,在 Key 與 Value 的使用上需要注意:Redis 的 Value 的上限為 512MB。
Redis 底層使用 Array 作為資料結構,Key 儲存在 Array 時,會先透過 Hash Function 來計算,並且再取餘數來決定 Key 的位置。如果 Hash Function 有衝突,Redis 會使用 Linked List 來解決。
Redis 的 key 的表示方式,可以使用 : 來區分不同的 key,例如 user:1000:username,用於表示資料的層級關係;也可以使用 - 來區分不同的 key,例如 user-1000-username,Key 的長度上限也是 512MB。
Redis 的 Key 有大小寫之分,所以
user:1000:username與User:1000:username是不同的 Key。
# 連接到 Redis 伺服器
redis-cli
# Strings
SET key "value"
GET key
DEL key
# Hashes
HSET key field1 value
HSET key field2 value2
HGET key field
HGETALL key
# Lists
LPUSH key value
LRANGE key 0 -1
LPOP key
# Sets
SADD key value1
SADD key value2
SMEMBERS key
SPOP key
SUNION key1 key2
SINTER key1 key2
SDIFF key1 key2
# Sorted Sets
ZADD key score member
ZRANGE key 0 -1
# Bitmap
SETBIT key offset value
GETBIT key offset
# Bitfield
BITFIELD key GET type offset
BITFIELD key INCRBY type offset increment
# Geospatial
GEOADD key longitude latitude member
GEOPOS key member可以透過 Keys * 來確認目前 Redis 伺服器上的所有 Key 以及值。
KEYS *
# 時間複雜度 O(N)
# 也可以篩選特定的 Key
SET user:1000:name "Nick"
SET user:1000:age 25
KEYS user:*💡 此外可以透過 SCAN 來進行查詢,可以改善 KEYS * 對於單一執行緒所造成的阻塞問題,藉由的方式是透過 Cursor 來進行查詢。
SCAN 0 # 0 表示從頭開始查詢
SCAN 0 MATCH user:* # 查詢特定的 KeyStrings
最簡單與最常用的資料結構,可以儲存字串、整數、浮點數,同時兼具字串與整數的功能,可以進行加減乘除的運算。會根據資料的特性來決定資料的類型,包含 long, int, embstr 或 raw 等型別。
SET counter "100"
INCR counter # 101
DECR counter # 100
INCRBY counter 10 # 110
DECRBY counter 10 # 100
STRLEN counter # 3也可以當作字串來操作
APPEND counter "0" # 1000
GETRANGE counter 0 2 # 100
可以透過 object encoding 來查看資料的類型。
OBJECT ENCODING counter # int如果要大量設定,可以使用 MSET 來設定多個 Key-Value Pair,這樣效能會比多次使用 SET 更好。
MSET key1 value1 key2 value2 key3 value3如果要確認 Key 是否存在,可以使用 EXISTS 來確認,與直接使用 GET 來確認是否為 nil 的效能上會比較好。
EXISTS key可以為 Key 設定過期時間,可以使用 EXPIRE 來設定過期時間,單位為秒。
EXPIRE key 10 # 10 秒後過期在寫入資料時,可以加上 NX 或 XX 來確認是否存在等條件,來決定是否寫入資料。
| Option | Description |
|---|---|
| NX | Only set the key if it does not already exist. |
| XX | Only set the key if it already exist. |
| EX | Set the specified expire time, in seconds. |
結合 NX 與 EX 可以建構 Distributed Lock:
Distributed Lock 用於在分散式系統中確保多個節點不會同時執行某些關鍵區段的代碼。這對於避免競爭條件和確保數據一致性非常重要。
# client 1
SET lock "1" NX EX 10 # 設定 lock 10 秒後過期
# client 2
SET lock "1" NX EX 10 # 無法設定,因為 lock 已經存在
# 10 秒後
# client 2
SET lock "1" NX EX 10 # 可以設定,因為 lock 已經過期其他還有一些騷操作,例如透過 SETBIT KEY OFFSET VALUE 來設定 Bit 的值,透過 GETBIT KEY OFFSET 來取得 Bit 的值。
Dump 可以將 Key 的 Value 轉換成二進制的格式,可以透過 DUMP 來取得,RESTORE 來還原。
SET key 123
DUMP key # "\x00\xc0{\x0c\x00\x83\x94g!\xfaP\xf9\xf0"
RESTORE key 0 "\x00\xc0{\x0c\x00\x83\x94g!\xfaP\xf9\xf0" REPLACE注意,
RESTORE預設是不會取代已經存在的 Key,如果要取代,需要加上REPLACE。
List
List 是有順序的資料結構,可以進行 Push、Pop 的操作,也可以當作 Stack 或 Queue 來使用。
| Command | Description |
|---|---|
| LPUSH | Push element to the head of the list. |
| RPUSH | Push element to the tail of the list. |
| LPOP | Pop element from the head of the list. |
| RPOP | Pop element from the tail of the list. |
| LRANGE | Get a range of elements from the list. |
| LINDEX | Get an element from the list by its index. |
| LLEN | Get the length of the list. |
| LINSERT | Insert an element before or after another element in the list. |
| LREM | Remove elements from the list. |
| LSET | Set the value of an element in the list by its index. |
| LTRIM | Trim the list to the specified range. |
LPUSH L 1 # 1
LPUSH L 2 # 2, 1
LPUSH L 3 # 3, 2, 1
LRANGE L 0 -1 # 3, 2, 1此外有 Blocking Pop 的操作,可以透過 BLPOP 或 BRPOP 來進行 Blocking Pop 的操作。處理的對象是一個空 List,客戶端會進入 Blocking 狀態,直到有元素被 Push 進來,馬上將此元素取走,這使得客戶端能夠高效地等待資料,而無需不斷輪詢列表狀態。
| Command | Description |
|---|---|
| BLPOP | Blocking Pop element from the head of the list. |
| BRPOP | Blocking Pop element from the tail of the list. |
LPUSH L 1
LPUSH L 2
LPUSH L 3
LBPOP L 0 # 3Move 相關操作,包含下列的命令。
| Command | Description |
|---|---|
| LMOVE | Move an element from one list to another. |
| LTRIM | Trim the list to the specified range. |
Hashes
Hashes 是一種 Key-Value 的資料結構,可以儲存多個 Key-Value Pair,可當作物件使用,適合儲存結構化資料,例如使用者資料、購物車資料等。
需要注意的是,Hashes 的 Value 不能是 List (所以 Client 端會將 List 轉換為 JSON 字串來儲存),只能是 String,不能是其他的資料結構。
在關聯式資料庫中,Hashes 相當於一筆記錄(Row),Key 相當於主鍵(Primary Key),Field 相當於欄位名稱(Column Name),Value 相當於欄位的值(Column Value)。在 MongoDB 中,Hashes 相當於 Document,而 Documents 的集合稱為 Collection。然而,Redis 沒有 Collection 或 Table 的概念。
Hashes 的底層資料結構會依據資料特性使用 listpack 或 hashtable 等。需要注意,自 Redis 7 起,ziplist 已被 listpack 取代。
Hashes 的優點在於將相關資料儲存在一個 Key 中,可以減少 Key 的數量,在取得資料時可以搭配 HGETALL 來取得所有的資料,這樣效能會比多次使用 GET 來取得資料更好。
但缺點是不能設定單一欄位的過期時間,並且不支援 bit 操作 (好像還好 😅)
| Name | Mapping in Redis |
|---|---|
| SQL Row | Hash |
| SQL Column | Field |
| SQL Value | Value |
| SQL Table | N/A |
| NoSQL Document | Hash |
| NoSQL Field | Field |
| NoSQL Value | Value |
| NoSQL Collection | N/A |
使用 Python 將 Json 資料轉換成 Hashes:
user_data = {
"user_id": "1001",
"name": "Xiaoming",
"age": 25,
"email": "[email protected]",
"interests": ["coding", "gaming"]
}
# 將列表轉換為字串,因為 Redis Hash 只能存儲字串
user_data["interests"] = json.dumps(user_data["interests"])
# 使用 HSET 將資料存入 Redis
redis_key = f"user:{user_data['user_id']}"
client.hset(redis_key, mapping=user_data)
# 讀取並驗證資料
stored_data = client.hgetall(redis_key)
print("儲存的資料:", stored_data)
# 將 bytes 轉換為字串
decoded_data = {k.decode('utf-8'): v.decode('utf-8') for k, v in stored_data.items()}
# 解析 JSON 字串
decoded_data["interests"] = json.loads(decoded_data["interests"])
print("解碼後的資料:", decoded_data)Sets
Sets 是一種無序且唯一的資料結構,可以儲存多個元素,並且不會重複,適合用來儲存不重複的資料,例如使用者 ID、標籤等。
Sets 的底層資料結構會依據資料特性使用 intset 或 hashtable 等。
| Command | Description |
|---|---|
| SADD | Add element to the set. |
| SMEMBERS | Get all elements in the set. |
| SISMEMBER | Check if the element is in the set. |
| SCARD | Get the number of elements in the set. |
| SREM | Remove element from the set. |
| SUNION | Get the union of multiple sets. |
| SINTER | Get the intersection of multiple sets. |
| SDIFF | Get the difference of multiple sets. |
SADD S 1
SADD S 2
SADD S 1
SMEMBERS S # 1, 2
SADD S2 3
SADD S2 1
SINTER S S2 # 1Sorted Sets
Sorted Sets 是一種有序且唯一的資料結構,可以儲存多個元素,並且可以設定分數,適合用來儲存排名資料,例如排行榜、投票等。不同於 Sets,Sorted Sets 會根據分數來排序,而 Sets 是無序的。
Sorted Sets 的底層資料結構會依據資料特性使用 ziplist 或 skiplist 等。
| Command | Description |
|---|---|
| ZADD | Add element to the sorted set. |
| ZRANGE | Get a range of elements from the sorted set. |
| ZRANK | Get the rank of an element in the sorted set. |
| ZSCORE | Get the score of an element in the sorted set. |
| ZREM | Remove element from the sorted set. |
| ZINCRBY | Increment the score of an element in the sorted set. |
| ZUNION | Get the union of multiple sorted sets. |
| ZINTER | Get the intersection of multiple sorted sets. |
ZADD EnglishTest 75 "Alice"
ZADD EnglishTest 80 "Bob"
ZADD EnglishTest 65 "Charlie"
ZRANGE EnglishTest 0 -1 # Charlie, Alice, Bob
ZRANGE EnglishTest 0 -1 REV # Bob, Alice, Charlie (Sort in Descending Order)
ZADD EnglishTest 90 "Alice"
ZRANGE EnglishTest 0 -1 REV # Alice, Bob, Charlie另外有 Store 相關操作,可以將結果存入另一個 Sorted Set 中,例如 ZUNIONSTORE 或 ZINTERSTORE。
ZUNIONSTORE 用於計算多個有序集合的聯集,並將結果存儲到新的鍵中。它會將所有集合中的成員分數進行匯總(預設是相加)。
假設我們在開發一個電商網站的商品推薦系統:
依據用戶瀏覽次數的商品分數,依據用戶購買次數的商品分數,並整合這兩個維度來產生最終推薦分數。
# 建立瀏覽次數的有序集合
redis-cli ZADD browse_scores 3 "product:1" 2 "product:2" 5 "product:3"
# 建立購買次數的有序集合
redis-cli ZADD purchase_scores 2 "product:1" 4 "product:2" 1 "product:3"
# 計算綜合分數
redis-cli ZUNIONSTORE final_scores 2 browse_scores purchase_scores WEIGHTS 0.3 0.7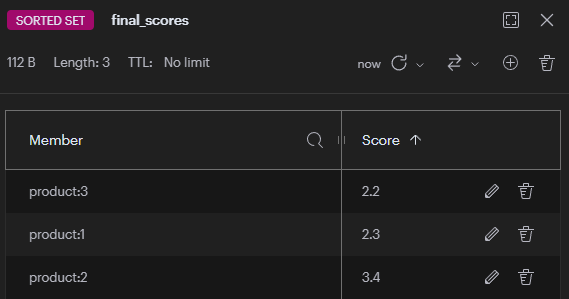
Redis Transactions
Redis 可以一次執行多個命令,並且保證這些命令的原子性,這稱為 Redis Transactions。Redis Transactions 通常用於保證多個命令的原子性,並且不會被其他客戶端的命令插入所影響。
實作上的概念是,Redis 將所有的指令放入一個 Queue 中,直到 EXEC 時才執行 (注意,在 EXEC 之前,不會執行任何指令),這樣可以確保所有的指令都是原子性的。
藉由 MULTI 開始 Transaction,EXEC 結束 Transaction,DISCARD 放棄 Transaction。經過實驗,如果 MULTI 後還沒有 EXEC,其他的 Client 仍然是可以操作其他的 Key。
MULTI
DECRY user:1000:balance 100
INCR user:1000:points 25
EXEC對應的操作方式在 Python 的 Redis Client 中,可以使用 pipeline 來進行操作。
with client.pipeline() as pipe:
pipe.decr("user:1000:balance", 100)
pipe.incr("user:1000:points", 25)
pipe.execute()而如果要 Rollback 的話,可以使用 DISCARD 來放棄 Transaction。
MULTI
DECRY user:1000:balance 100
DISCARDPython 中的操作方式如下:
with client.pipeline() as pipe:
pipe.decr("user:1000:balance", 100)
pipe.discard()GeoSpatial
GeoSpatial 是一種地理空間資料結構,可以儲存地理位置的資料,並且可以進行距離計算,適合用來儲存地理位置資料,例如商家、餐廳等。
GeoSpatial 是透過 ZSET 來實現,將經緯度轉換成 Score,並且將地點名稱轉換成 Member,這樣就可以進行距離計算。
| Command | Description |
|---|---|
| GEOADD | Add geospatial data to the key. |
| GEOPOS | Get the geospatial data of the member. |
| GEODIST | Get the distance between two members. |
| GEORADIUS | Search geospatial data in the key. |
| GEORADIUSBYMEMBER | Search geospatial data in the key. |
| GEOHASH | Get the geohash of the member. |
GEO 沒有刪除的操作,如果要刪除的話,可以直接將 Key 刪除。
詳細資訊可以參考 GeoHash。
# 新增多個餐廳位置
GEOADD restaurants 121.5645 25.0330 "restaurant:1" 121.5623 25.0335 "restaurant:2" 121.5657 25.0320 "restaurant:3"
# 取得特定餐廳的座標
GEOPOS restaurants "restaurant:1"
# 121.5645, 25.0330
# 計算兩間餐廳的距離(單位:公尺)
GEODIST restaurants "restaurant:1" "restaurant:2" m
# 228.5
# 搜尋特定餐廳半徑 1 公里內的其他餐廳
GEORADIUS restaurants 121.5645 25.0330 1 km WITHCOORD WITHDIST
# 搜尋指定餐廳周圍 500 公尺內的餐廳
GEORADIUSBYMEMBER restaurants "restaurant:1" 500 m WITHCOORD WITHDIST應用潛力龐大,可以構成動態的地理位置服務,呈現豐富的視覺化效果。
HyperLogLog
HyperLogLog 是一種用於估算基數 (Cardinality) 的資料結構,可以用來計算獨立元素的數量,適合用來計算網站的瀏覽量、訪問量等。對於處理大數據的場景,HyperLogLog 可以有效地減少記憶體的使用,並且可以在不同的節點上進行計算,最後再進行合併。
但 HyperLogLog 只能計算 Count 不能計算 Value,並且有一定的誤差率,誤差率通常在 0.81% 左右。
為什麼會有誤差?
- 雜湊碰撞:不同的元素可能產生相同的雜湊值,這種碰撞會導致計數偏差
- 取樣估算:HyperLogLog 不會儲存完整的元素資訊,使用機率統計方法進行估算,犧牲精確度換取極低的記憶體使用量
# 新增元素到 HyperLogLog
# 將 user1, user2, user3 新增到 2023-10-01 的訪客記錄中
PFADD visitors:2023-10-01 user1 user2 user3
# 計算 HyperLogLog 中的基數
# 計算 2023-10-01 的獨立訪問者數量
PFCOUNT visitors:2023-10-01
PFADD visitors:2023-10-02 user2 user3 user4 user5 user6 user7
# 合併多個 HyperLogLog
# 將 2023-10-01 和 2023-10-02 的訪客記錄合併到 total 記錄中
PFMERGE visitors:total visitors:2023-10-01 visitors:2023-10-02
# 計算合併後的基數
# 計算合併後的總獨立訪問者數量
PFCOUNT visitors:total如果使用工具檢視 (RegisInsight) HyperLogLog 的資料,會發現資料是以二進制的方式儲存的 😲
Streams
Streams 是一種有序且持久的資料結構,可以儲存多個事件,並且可以進行消費,適合用來儲存事件日誌、消息隊列等。
Stream 的基本概念,Stream 是一個有序的消息列表,每個消息都有一個唯一的 ID。而 Entry 是 Stream 中的一個消息,包含 ID 和 Field-Value Pair。Consumer Group 是一個消費者組,可以有多個消費者,每個消費者都有一個消費者 ID,並且可以進行消費。
Streams 的底層資料結構會依據資料特性使用 listpack 或 radix tree 等。
| Command | Description |
|---|---|
| XADD | Add event to the stream. |
| XLEN | Get the length of the stream. |
| XRANGE | Get a range of events from the stream. |
| XREAD | Read events from the stream. |
| XDEL | Delete events from the stream. |
| XACK | Acknowledge events from the stream. |
| XREADGROUP | Read events from the stream in a group. |
| XPENDING | Get the pending events from the stream. |
# 新增事件到 Stream,其中 * 表示自動產生 ID
XADD notifications * type alert message "a new message added"
# 使用 redis-cli 取得 Stream 的長度
XLEN notifications
# 使用 redis-cli 取得 Stream 中的一段事件,- 表示最新的事件 + 表示最舊的事件
XRANGE notifications - +
# 也可以使用 COUNT 來限制取得的事件數量
XRANGE notifications - + COUNT 3
# 使用 redis-cli 讀取 Stream 中的事件,其中 1733 表示 ID Pattern
XREAD COUNT 2 STREAMS notifications 1733
# 使用 redis-cli 刪除 Stream 中特定 ID 的事件
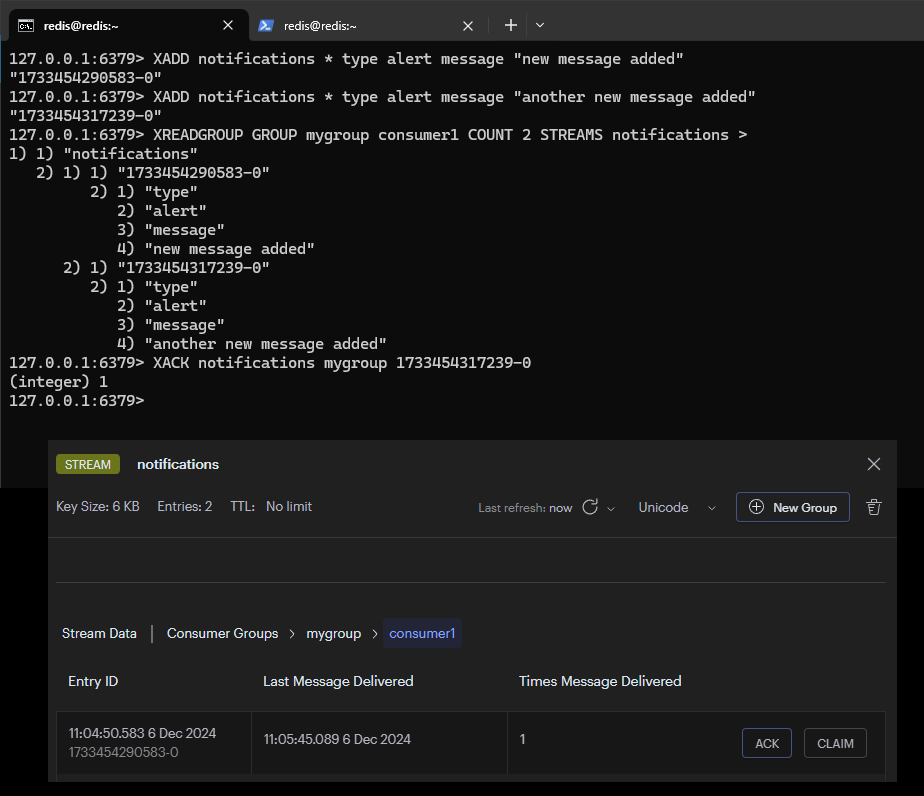
XDEL notifications 1609459200000-0Consummer Group 的操作方式如下:
XGROUP CREATE notifications mygroup $ MKSTREAM
XREADGROUP GROUP mygroup consumer1 COUNT 2 STREAMS notifications >
XACK notifications mygroup 1733453856521-0加入兩組訊息進入 Stream,首先是第一組訊息
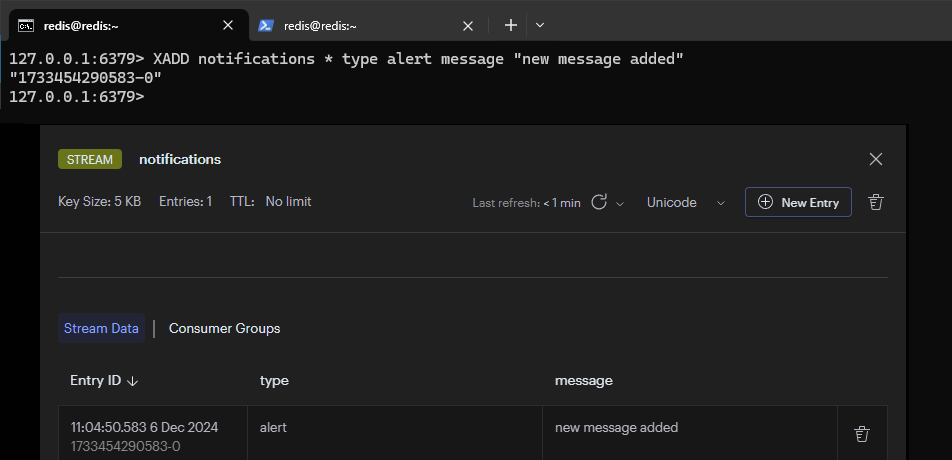
接著是第二組訊息,加入後的結果如下圖
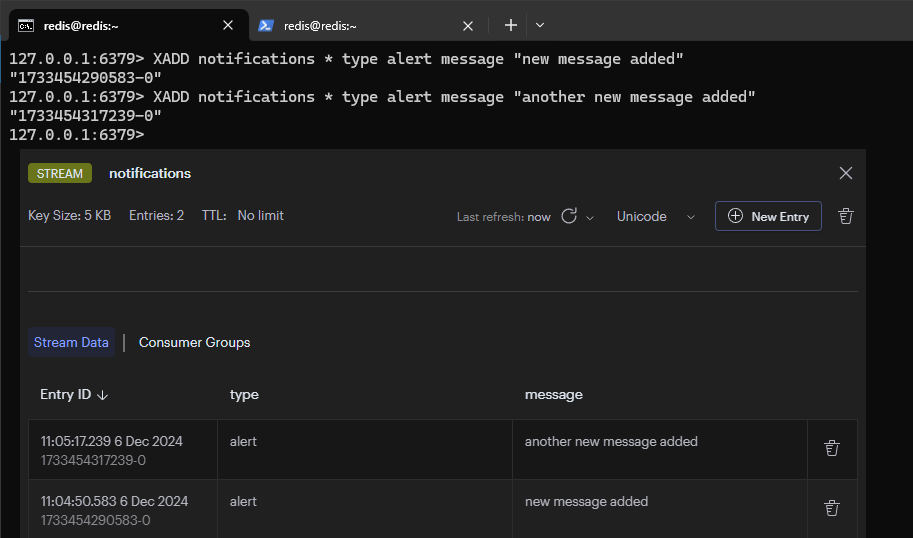
接著將兩組訊息加入到 Consumer Group 中
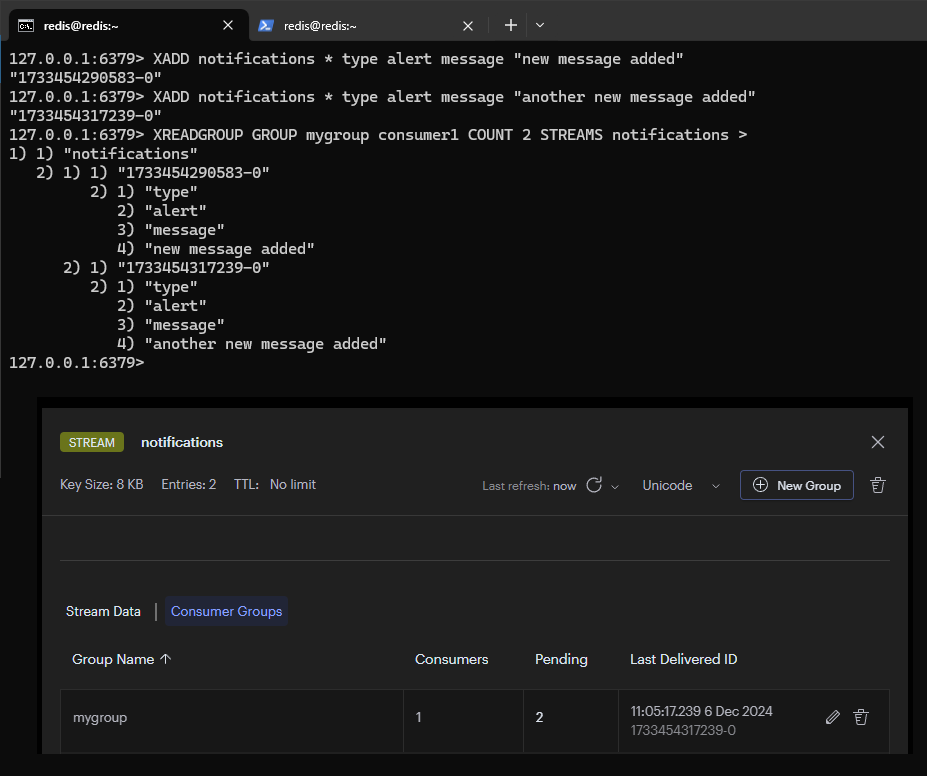
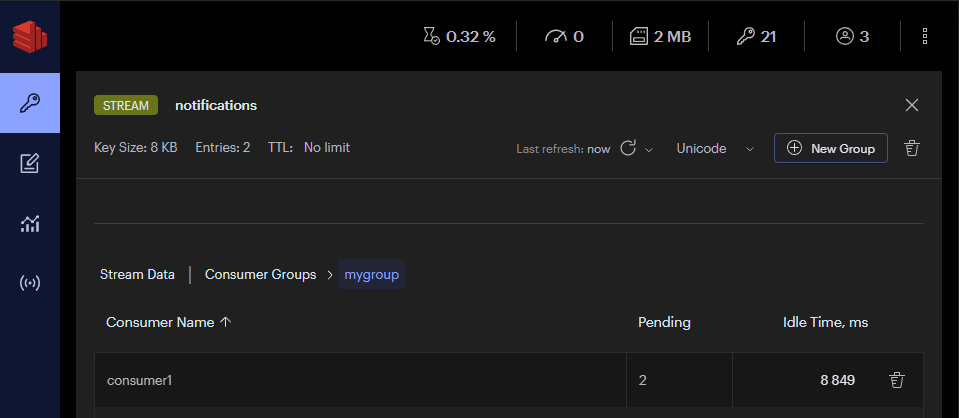
從 Consumer Group 中的 Consumer1 觀察到有兩組訊息狀態是 Pending
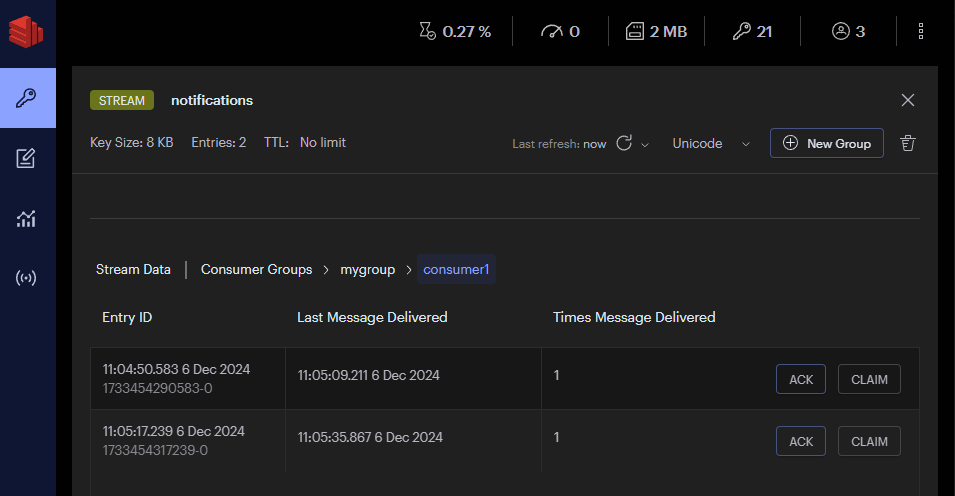
對於其中一筆訊息執行 XACK 指令後,訊息狀態變為 Acknowledged,並且從 Consumer1 當中消失