Generative AI With LM Studio & Ollama
2024-04-27
介紹如何使用 LM Studio 以及 Ollama 在個人電腦上運行 LLM,藉由 AI Chat, Playground 以及 API Server 來自助式打造 AI 應用。
同時也介紹 Groq 在雲端上部署 LLM 結合 API 來使用。

LM Studio
LM Studio 簡化了要從 huggingface 下載各式開源模型 (Facebook llama, Google Gemma) 再透過 python torch 執行的繁瑣步驟。
只需要安裝 LM Studio 接著透過內建的 Model Search 下載模型,掛載模型後就可以透過 AI Chat, Playground 以及 API Server 來測在個人電腦運行 LLM。
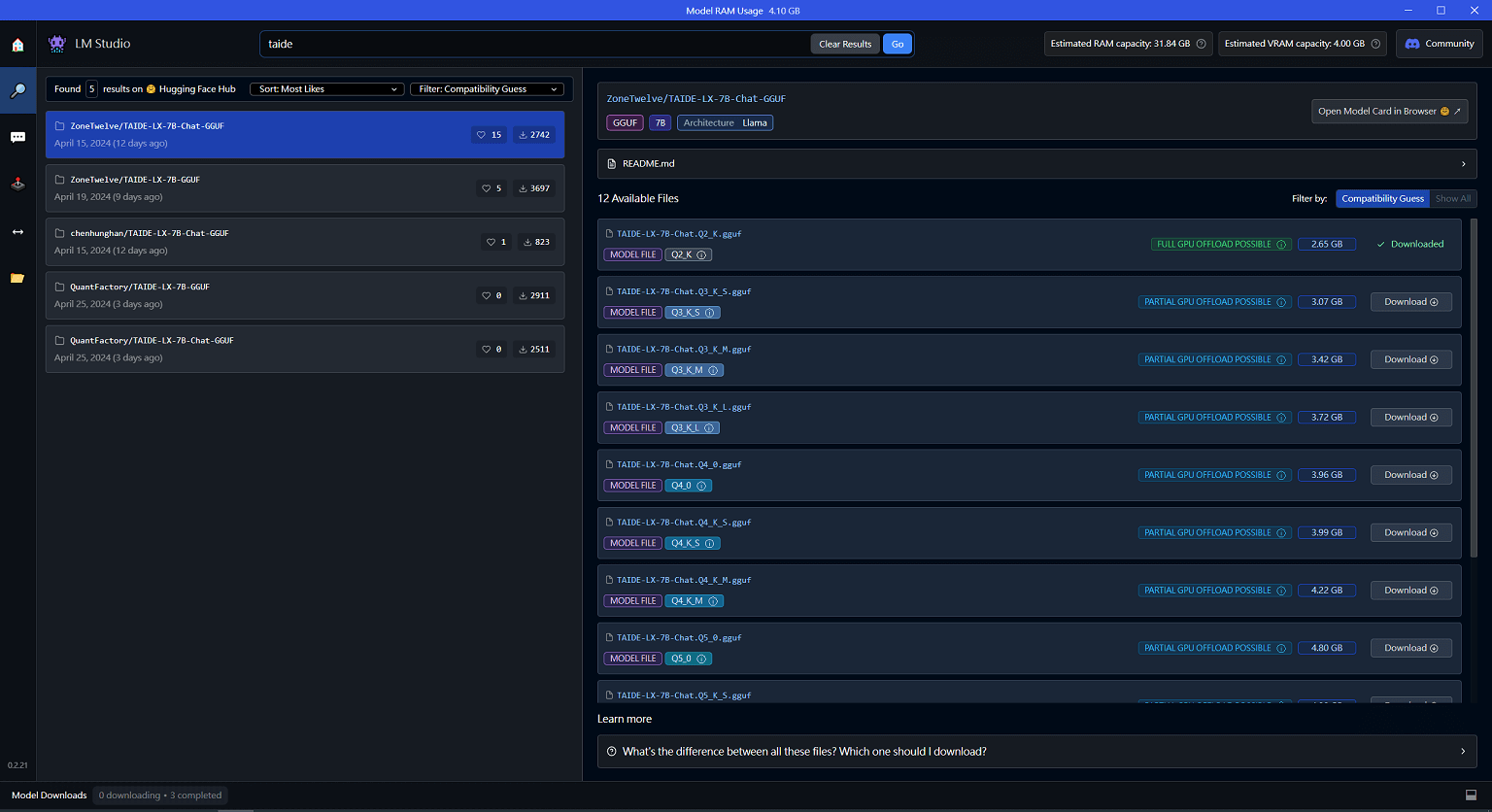
因為是在個人電腦上執行,所以個人電腦的硬體設備相當重要,部分的模型在 LM Studio 搜尋時,會判斷個人電腦無法順利執行 (顯示卡記憶體不夠) 而主動 Filter 不顯示 (可以主動搜尋,不過即使下載了可能也無法順利運行 😥)。
本次示範使用 Microsoft Phi-3 7B 模型,在 AI Chat 當中測試生成,與 Azure OpenAI 的介面相仿,但多了更多友善的功能 (複製、設定),最大優點是用介面的方式就可以達成 LLM 的下載、載入與管理 😀
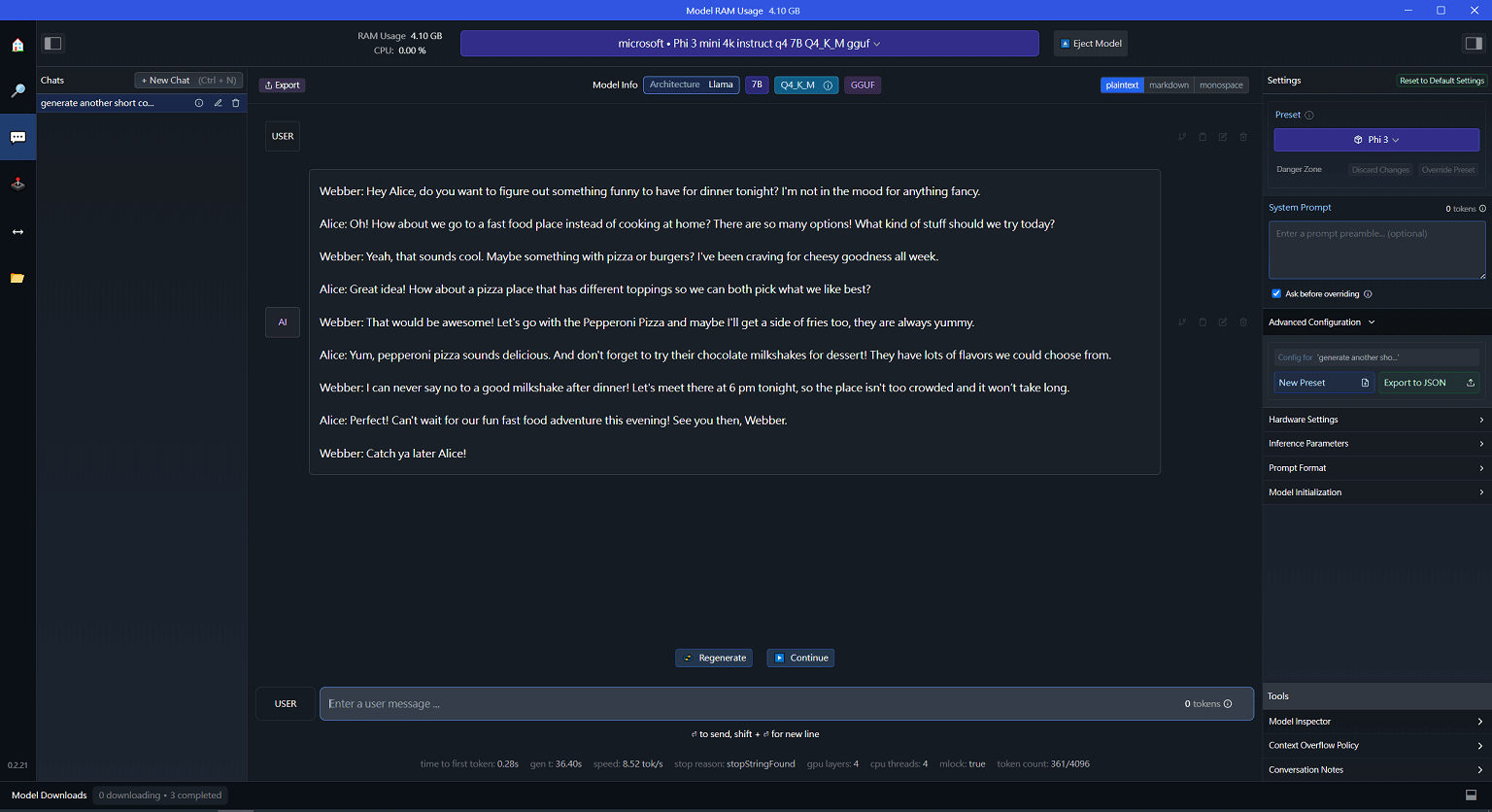
測試的硬體環境使用 Intel 10870H, 32GB, GTX 1650Ti 4GB,硬體環境要執行 LLM 相當勉強,即使是相當輕量的 Phi-3 7B,每秒鐘大約產生 8.5 Token。

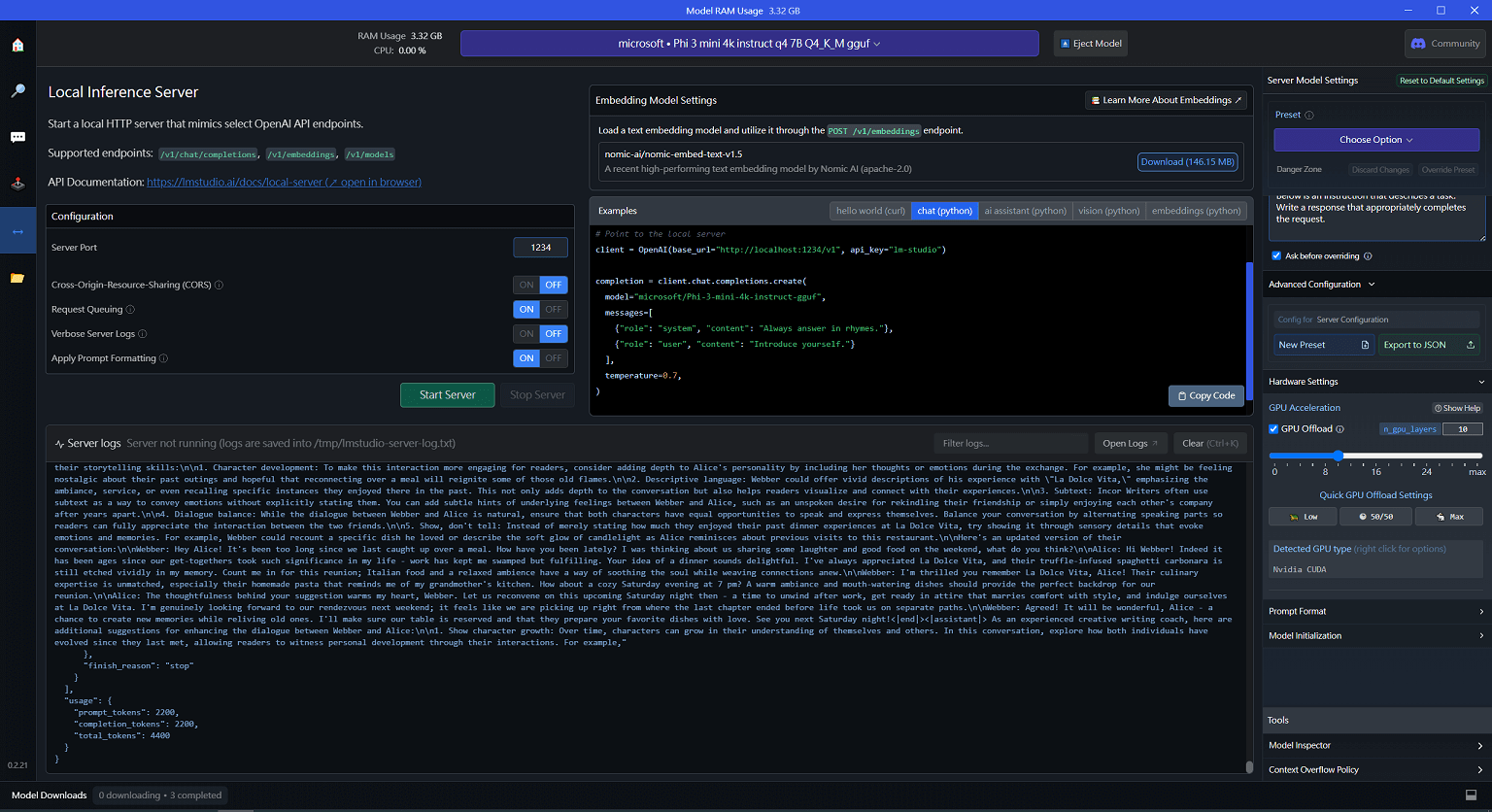
要結合應用程式使用通常會包裝為 API 的方式,LM Studio 也已經提供此功能,只需要啟用 API Server 就可以根據自定義的 port 來使用,非常方便。
Ollama
參考保哥的介紹 介紹好用工具:Ollama 快速在本地啟動並執行大型語言模型 | The Will Will Web,如果不想要安裝 LM Studio,可以改用 Ollama 並且搭配 Docker 的方式來運行,
docker run --name ollama -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 ollama/ollama
docker exec -it ollama ollama run phi3:mini其他熱門的模型也可以透過 Ollama 來運行。
docker exec -it ollama ollama run phi3.5
docker exec iit ollama ollama run jcai/llama3-taide-lx-8b-chat-alpha1:Q4_K_M不同於 LM Studio 的完整 GUI,Ollama 是提供 CLI 的操作方式,但同樣有提供 API Server 的方式。
不過差別在於 LM Studio 可以相容 OpenAI API,所以直接在 python 使用 openai-python 就好,但在 ollama 需要安裝 ollama-python 來使用 ollama 的 restful api。
示範如何透過 PostMan 來 Post 至 ollama api,注意要使用 json format 當作 payload。
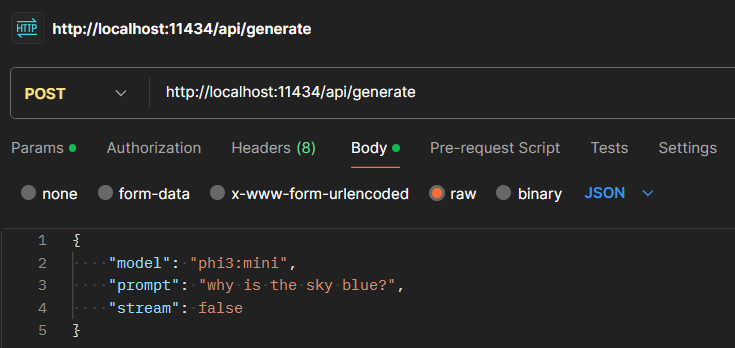
Groq
但礙於硬體本身的限制,要想這些模型還是透過 Cloud Service 的方式比較方便,Groq 提供了流量限制的免費 API 可供使用,如果想要流暢的回應速度,可以透過 Groq 來部署這些模型搭配 API 方式使用。