SQL Server Developing SQL Databases
2021-11-27
筆記 20762 - Developing SQL Server 學習心得以及反思具體可以用於資料庫開發與管理的實踐。項目包含資料庫壓縮、索引設計、索引檢視表、In-Memory Database、FileStream 以及各種資料庫物件的靈活使用,讓系統開發能夠與資料庫應用有更好的結合。
說明
設計和實施表
參考 AdventureWorks 的資料庫物件命名慣例:
- CamelCase
- 資料表不加 Prefix
- 善用 Schema 來管理資料庫物件
| Objects | Prefix | Example |
|---|---|---|
| Table | Schema | HumanResources.Employee |
| View | v | Sales.vSalesPerson |
| Stored Procedure | ups | dbo.uspPrintError |
| Clustered Index | PK_ | PK_Password_BusinessEntityID |
| NonClustered Index | IX_ | IX_Person_LastName_FirstName_MiddleName |
| Pirmary Key | PK_ | PK_Password_BusinessEntityID |
| Foreign Key | FK_ | FK_Password_Person_BusinessEntityID |
| Functions | ufn | dbo.ufnGetContactInformation |
💡 避免使用 Deprecated Data Types: text, ntext 等
💡 Datetime2 資料比 Datetime 更為精準
🐸 檢查資料表的相依關係
💡 臨時的資料表 tempdb 或者 @ 變數
進階資料表設計
🐸 Partition Table
利用分散於不同磁區的檔案群組,將資料表的資料列分散到不同的檔案群組中。用於增加資料讀寫速度,並於 archive 磁區的資料可以降低備份頻率。但如果資料庫伺服器沒有辦法使用多個讀頭讀寫磁區是否仍有使用價值?
需要先加入 FileGroup,並設計 Partition Function 以及 Partition Schema 以達到 Partition Table 的作用。
🐸 壓縮資料庫
資料庫的壓縮包含備份壓縮、資料庫壓縮用於釋放 SQL Server 佔據磁碟但未使用的空間,最後則是資料表壓縮。
資料表壓縮不是一次性的設定,而是會將資料表永遠保持在壓縮的情況下。優點是減少儲存空間,缺點是讀取需要運算時間。
🐸 Temporal Tables
應用程式需要客製追蹤資料表異動情形的解決方案。
資料完整性
💡 使用 Check
💡 使用 Constraint
- Default Constraint
- Primary Key Constraint
- Identity Constraint
- Foreign Key Constraint
🐸 Foreign Key & Cascading Referential Integrity
Indexs Design
資料表的資料列保存方式是以 8K Data Page 進行保存,在沒有叢集索引的情況下,資料表會以 Heap 的方式保存,其中子葉為 Data Page。而如果有叢集索引,則會按叢集索引的方式保存,子葉同樣為 Data Page,因此每張資料表只能有一個叢集索引(nvarchar(MAX) 等長文資料不是保存在 8K Data Page,而是另有專門的資料保存方式)。
而資料表的非叢集索引則可以高達 999 個,其子葉為 Heap 或者叢集索引的 Link。
資料表的索引,需要考慮實際使用的 Query 去做設計,而索引帶來最大的好處就是在搭配正確的 Query 之下能夠提升查詢的速度,但索引本身需要儲存空間,約為資料表的 40%,不可不謂一筆成本。此外索引在資料寫入、更新時會同步改變,因此會造成額外的效能需求。同時索引會隨著資料的異動有碎片化的問題發生,必須定期重組 (ReOrganize) 或者重建索引 (ReBuild)。
按照經驗法則 30% 以上的碎片化 (Fragmentation) 就需要進行 ReBuild。
索引的設計上必須根據實際使用情形,可量複合索引 (Composite) 此外複合索引的索引順序會影響查詢速度,Include Column 作為複合索引的特別需求解決方案。
並非建立索引 SQL Server 就會使用,SQL Server 有演算機制評估是否使用索引,可以從執行計畫上看到 SQL Server 是否使用索引,如果是 SCAN 就沒有,SEEK 則有。需要注意的是即使是 SCAN 索引,也是沒有使用索引的!
使用 Database Engine Tuning Advisor 可以由系統建議適合的索引建立。
🐸 關於 Fill Factor 的補充
🐸 關於 Merge Join, Hash Match, Nested Loop 的補充 (6-20)
索引的代價在於建立成本、儲存空間與維護成本
不適合作為索引的欄位有下列特性:重複值太多、經常修改以及長文類型資料。
Columnstore Index
以欄位的方式進行索引建立,適合資料倉儲的情境,可能有異想不到的效能優化功效。
View Deisgn
View 將資料查詢語句封裝後提供使用,可以限縮使用的資料欄位,並由多個資料表、資料來源做合併 (Join)。按照 AdeventrueWorks 的 Naming Convention 使用小寫 v 作為自首,在以 CamelCase 的方式命名,例如 vSalesPerson。
System View
SQL Server 預設提供了豐富好用的 System View,包括 Catalog View 以及 DMV 系列的 View,提供客製資料庫管理上所需要的各種查詢方式。
實用的 Catalog View
| Catalog | Level |
|---|---|
| sys.sysconfigures | Server |
| sys.assemblies | Server |
| sys.databases | Server |
| sys.sql_logins | Server |
| sys.servers | Server |
| sys.linked_logins | Server |
| sys.sysusers | Database |
| sys.tables | Database |
| sys.database_files | Database |
| sys.filegroups | Database |
| sys.foreign_keys | Database |
| sys.default_constraints | Database |
| sys.key_constraints | Database |
| sys.check_constraints | Database |
| sys.all_views | Database |
| sys.all_columns | Database |
Indexed View
將 View 實體化儲存於磁碟空間,可以提升查詢的效率,但會有寫入、更新的資料的額外成本,同時不是所有的 View 都能建立為 Indexed View,限制包含:
實際適用的場景如:
- 彙整函數的使用
- 簡單的大量資料表 Join
Partition View
將分散在多個來源(資料表、資料庫、資料庫伺服器)的資料表,利用 UNION ALL 結合為 View,提供單一的存取介面。
Create View vPartitionView
AS
SELECT * FROM Server1.MIS.Person
UNION ALL
SELECT * FROM Server1.FINANCE.Person
UNION ALL
SELECT * FROM Server2.SALES.PersonStored Procedure
Stored Procedure 將資料庫 CRUD 的動作封裝起來重複使用,並可以解決下列 View 沒有辦法做到的事情:
- Order By 等 SQL 語法
- Parameters 參數,讓 Stored Prcocedure CRUD 有著更為彈性的重複使用便利
- 多個 Select 語法並搭配 Temporary Table 來設計查詢
在設計 Stored Procedure 常會開頭搭配 SET NOCOUNT ON 來避免無關的資訊顯示,在錯誤提示上應使用 RAISEERROR() 函式來通知,而非使用 PRINT。
CREATE PROCEDURE AddNumbers
@N1 smallint,
@N2 smallint,
@SUM smallint OUTPUT
AS
SET NOCOUNT ON;
SET @SUM = @N1 + @N2
GO
Declare @Ans int
EXEC AddNumbers 3, 5, @Ans Output
SELECT @ANSUser Defined Function
| FunctionType | Usage |
|---|---|
| Scalar | 回傳單一值 |
| Table-Valued | 回傳資料表,可以做為 FROM 的來源 |
| Multistatement Table-Valued | 自行組建資料表並回傳 |
Trigger
Trigger 太多會拖慢資料庫的寫入、更新。但 Trigger 適合用於資料列內容修改時,自動更新欄位最後異動時間的使用情境。
| Name | Type | Usage |
|---|---|---|
| Update Trigger | Trigger | 在資料被更新時觸發,進行資料的修改,可用於修改編輯時間等 |
| Instead Of Trigger | Trigger | 修改欄位而非刪除資料 |
CREATE TRIGGER del_ins_trigger1
ON [Order details]
instead of delete
AS
BEGIN
SET NOCOUNT ON;
update [Order Details] set deleted = 1
from [Order Details] as od inner join deleted as d
on od.OrderID = d.OrderID and od.ProductID = d.ProductID
END
GOIn-Memory Table
藉由將資料表儲存於記憶體中,達到極快速的資料讀取與寫入速度,尤其適合需要大量寫入以及刪除資料的資料表使用情境。
而要讓 In-Memory Table 發揮最佳的效能,必須搭配 Native StoredProcedures。
在使用時,必須先建立 Memory Optimized Data 的 FileGroup,在於資料庫中加入新的 Database File。
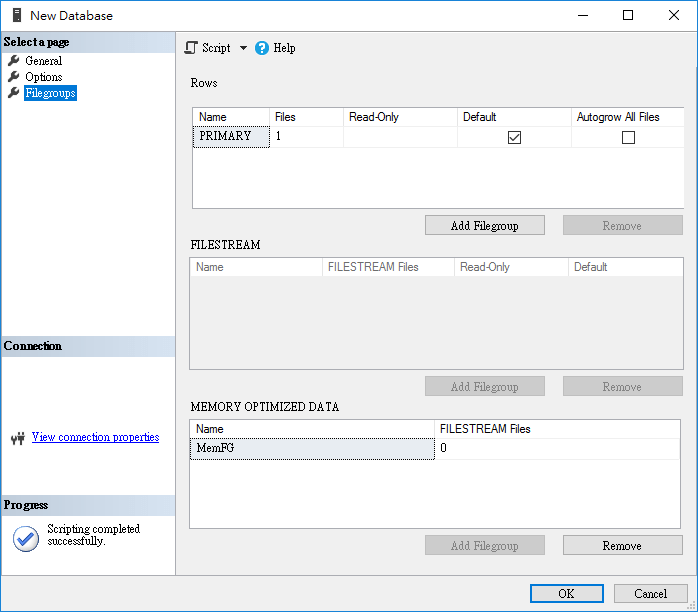
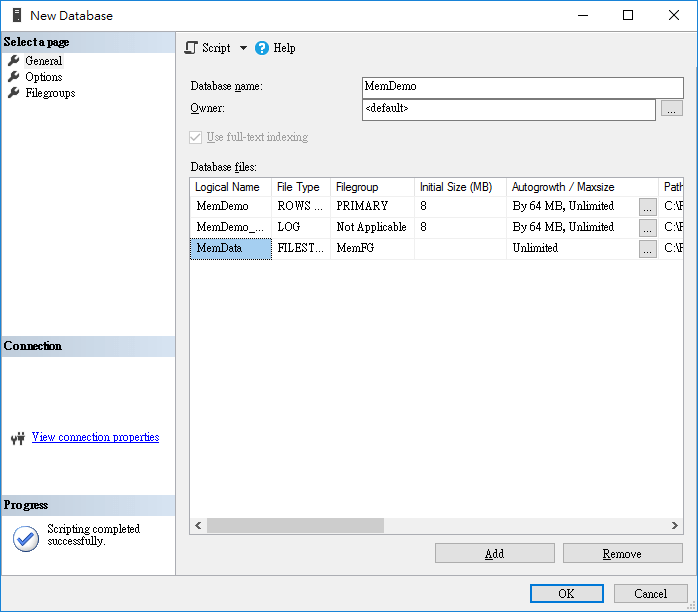
建立資料表時,因為 In-Memory Table 不支援 Clustered Primary Key ,因此 Primary Key 必須指定為 NonClustered。
USE MemDemo
GO
CREATE TABLE dbo.MemoryTable
(id INTEGER NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1000000),
date_value DATETIME NULL)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);下表為作為對照用的 Table 使用 Disk Filegroop。
CREATE TABLE dbo.DiskTable
(id INTEGER NOT NULL PRIMARY KEY NONCLUSTERED,
date_value DATETIME NULL);在效能的驗證上,Disk Table 大約花費 10 秒完成資料寫入;Memory Optimized Table 則約 5 秒。
Memory Optimized
BEGIN TRAN
DECLARE @Memid int = 1
WHILE @Memid <= 500000
BEGIN
INSERT INTO dbo.MemoryTable VALUES (@Memid, GETDATE())
SET @Memid += 1
END
COMMIT;Disk
BEGIN TRAN
DECLARE @Diskid int = 1
WHILE @Diskid <= 500000
BEGIN
INSERT INTO dbo.DiskTable VALUES (@Diskid, GETDATE())
SET @Diskid += 1
END
COMMIT;確認目前 MemoryTable 的資訊:
SELECT o.Name, m.*
FROM
sys.dm_db_xtp_table_memory_stats m
JOIN sys.sysobjects o
ON m.object_id = o.id
而一旦結合 Native Stored Procedure 後,可以得到 ms 等級的完成速度,甚至將規模放大為 5,000,000 也只需要約 4 秒😮
CREATE PROCEDURE dbo.InsertData
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = 'us_english')
DECLARE @Memid int = 1
WHILE @Memid <= 500000
BEGIN
INSERT INTO dbo.MemoryTable VALUES (@Memid, GETDATE())
SET @Memid += 1
END
END;
DELETE FROM dbo.MemoryTable
EXEC dbo.InsertData;SQL Server FileStream
🐸 如何使用 FileStream 並結合 FileGroup 的設定,讓應用程式可以將 BLOB 檔案儲存於資料庫伺服器的 FileSystem,並使用 FileTable 來管理檔案的異動紀錄。
SQL Server Concurrency
釐清 Share Lock、Update Lock、Exclusive Lock 以及 Intent Lock。
從交易機制去解決 Lock 問題。
💡 資料庫應該開始 Read_Committed_SnapShot 設定,避免查詢上的 Lock。
冷知識
- SQL Server 如何實作 .NET 物件 以及載入 ASSEMBLY
- Spacial Data Type
Terms
- Foreign Key
- ...
- Surrogate Key
- ...
- Seek
- ...
- Scan
- ...
- ColumnStore Index
- ...
- Clustered Index
- ...
- NonClustered Index
- ...
- Query Store
- ...
- Database Engine Tuning Advisor
- ...
- Excution Plans
- ...
- Heaps
- ...
- Composite Indexes
- ...
- Temporal Tables
- ...
- Temorary Tables
- ...
- Index Fragmentation
- ...
- Covering Index
- ...
- Fill Factor
- ...
- Pad Index
- ...
- Constraints
- ...
- Dynamic Management Views
- ...
- Catalog Views
- ...
資料庫物件
| Name | Type | Usage |
|---|---|---|
| Indexed View | View | 實體化的 View,增加查詢效率,以儲存空間為成本 |
| Partitino View | View | 利用 UNION ALL 將 View 分散在多資料庫、伺服器 |
| Simple Select | Stored Procedures | 相較於 View 支援 Order By |
| Parametered | Stored Procedures | 可以使用參數的方式傳入資料 |
| Result | Stored Procedures | 可以將結果保存並進行回傳 |
| Cross DB | Stored Procedures | 需要注意 Permissions 的問題 |
| Scalar | Function | 可以回傳單一數值,需要注意 Loop 效能問題 |
| Table-Valued | Function | 可以將結果回傳為 Table,只能單一 Select |
| Multistatements Table-Valued | Function | 自行定義空白 Table 並使用多組 Select 填充資料後回傳 Table |