Python 使用 PyPDF2 存取 PDF 文件屬性 (Python Using PyPDF2 Access & Edit PDF Metadata)
2021-08-03
最近有處理 PDF 文件屬性的需求,第一時間想到的就是 GitHub 的開源工具,但嘗試了一下發現沒有辦法如期使用,於是改採用 Python 並使用 PyPDF2 進行處理。本篇作為使用 PyPDF2 處理 PDF 文件屬性的教學文件,包含 PyPDF2 的安裝以及提供 PyPDF2 Example。
說明
安裝 PyPDF2
pip install PyPDF2讀取 PDF 文件屬性
from PyPDF2 import PdfFileReader, PdfFileWriterwith open('file.pdf', 'rb') as f:
pdf = PdfFileReader(f)
metadata = pdf.getDocumentInfo()getDocumentInfo 回傳為 DocumentInformation 資料結構,此資料結構繼承了 Python Dictionary。預設有下列 property:
| 屬性 | 說明 |
|---|---|
| author | 作者 |
| creator | 應用程式 |
| producer | PDF 轉換工具 |
| title | 標題 Chrome 瀏覽器預設會顯示 |
| subject | 也翻譯為標題,但顯示於不同欄位 |
以上的屬性可以直接存取,如果不存在會以 None 回復。
[
metadata.author, metadata.creator,
metadata.producer, metadata.subject,
metadata.title
]此外也可以使用 keys() 來檢查 pdf 其他的文件屬性,常見的例如 CreationDate, Creator, ModDate, Keywords 等:
metadata.keys()
# dict_keys(['/CreationDate', '/Creator', '/ModDate', '/Producer', '/Title'])可以使用此方式存取,注意須包含正斜線
metadata['/CreationDate']上述的屬性對應到 Chrome 文件屬性的畫面如下:
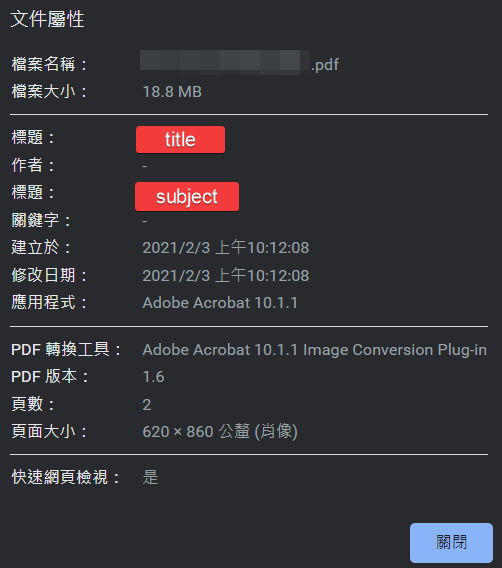
編輯 PDF 文件屬性
fin = open('file.pdf', 'rb')
fout = open('new.pdf', 'wb')
reader = PdfFileReader(fin)必須先將原本的 pdf 檔案加入回 writer 當中,並且再把 metadata 也加入 writer,最後再將 writer 寫入 file 當中。概念上就是重新製作 PDF 檔案,而非操作預期上的修改檔案。
writer = PdfFileWriter()
writer.appendPagesFromReader(reader)
writer.addMetadata(metadata)
writer.write(fout)應用
批次讀取 PDF Metadata 匯出為 CSV
...
批次進行 PDF Metadata 修改並另存新檔
...